
TARVU is dead; long live JELTZ
On Thursday, Feb 17th, around about 1:30p, my server machine ("TARVU") failed to come back from an "unplanned shutdown". Three days later, JELTZ has risen from its ashes.
Thursday, Feb 17th, ~1:30p
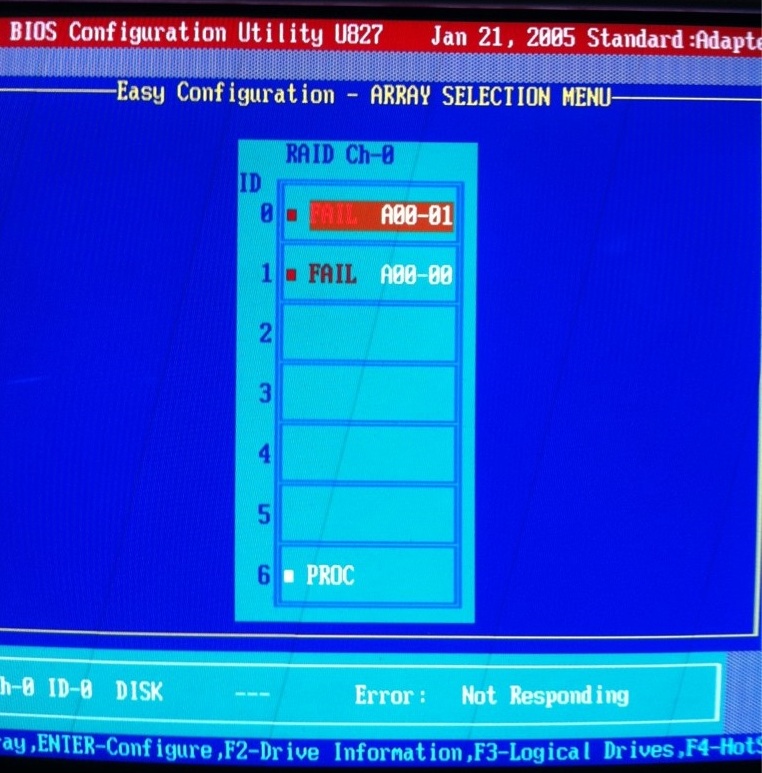
TARVU experiences an "unplanned shutdown". The UPS through which it is powered failed to maintain power (despite having already been plugged back into the mains!) causing TARVU to go offline. On bootup, the SCSI controller reported that the logical drive had failed, and would I care to press Ctrl-M to continue? Obligingly, I discovered that the controller was reporting both physical drives (RAID 1) as "FAIL". I found it hard to believe that both drives failed simultaneously and, instead, choose to believe that the SCSI controller was faulty. This theory was reinforced when, having swapped the position of the drives, the controller failed to even acknowledge their presence.
Thursday, Feb 17th, 7:25p
Having spent six hours futzing about, randomly, with the SCSI drives and BIOS settings, I declared myself stumped and turned to the internet for assistance. A photo of the situation illustrated the problem.
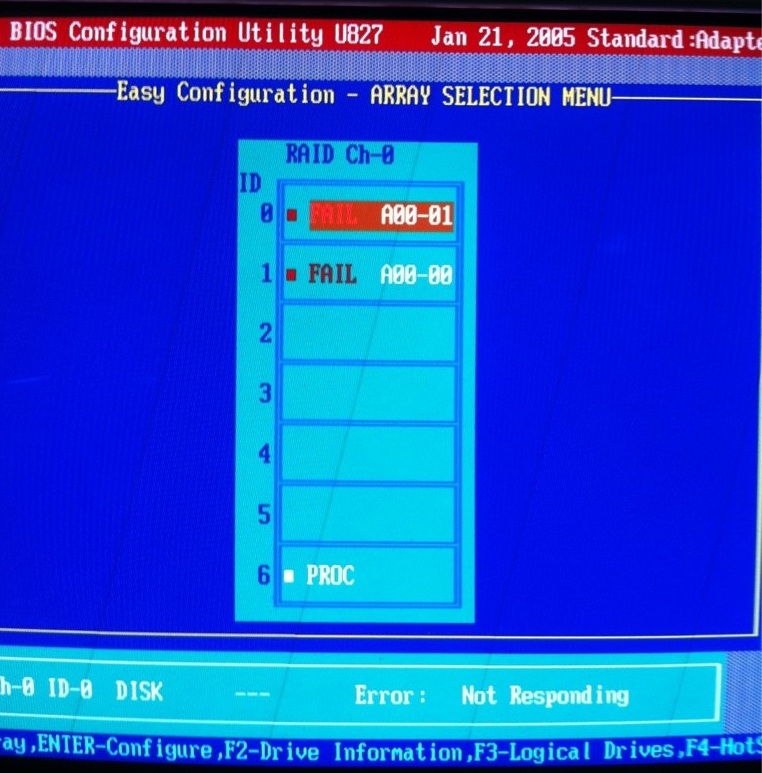{kind=link}
Friday, Feb 18th, 10:53a
I decided the thing to do was to get my hands on some known good SCSI drives of similar type and to figure out whether it was the drives or the controller that had gone bad. Since I had acquired the decommissioned Dell PowerEdge from my employer I figured there might be other, similar sets of hardware stuffed in a closet somewhere.
Friday, Feb 18th, 3:59p
I was right. I found two pairs of similar SCSI drives and, in fact, an entire Dell server (of a somewhat older vintage) crammed in one of our junk closets. When I put my SCSI drives in the old server its controller reported them as "ONLIN" (though it wouldn't boot - but this was expected). So the drives were fine!
Friday, Feb 18th, 9:39p
My server's SCSI controller finally decided to acknowledge the presence of the drives. Using the PERC BIOS I forced one them back online and was finally able to boot to the OS login screen. I declared "Good news! Expect normality to return within the next thirty minutes." Boy, was I wrong.
Friday, Feb 18th, 9:52p
Something was wrong. Windows got stuck in an infinite reboot cycle. It would get to the OS loading screen, then simply reboot. I abandoned that course and instead returned to an investigation of the drives. Since the drives were in a mirrored array I told the controller to check drive consistency and, since that was going to take a couple hours, finally went to bed.
Saturday, Feb 19th, 7:15a
I couldn't sleep so I got up to check on the server. The consistency check came back successful, but the OS was exhibiting infinite reboots. I tried rebuilding the RAID array a couple times; ultimately it was a lost cause. There was too much file damage to the drive for the OS to function.
Saturday, Feb 19th, 10:47a
Found a Windows 2003 Server CD and tried to "repair" the operating system. It would sail along for quite some time and, then... BSoD.
Saturday, Feb 19th, 10:47a
After one too many "PAGE_FAULT_IN_NONPAGED_AREA" BSoDs I decided that repairing wasn't going to work and that I would have to simply reinstall the OS.
Saturday, Feb 19th, 9:28p
Having spent the entire [fucking] day rebuilding the OS I had finally gotten far enough along that its primary purpose was met and I went to bed, again.
Sunday, Feb 20th, 3:21p
Spent the entire day rebuilding everything else (client sites, email, this very blog site, backup routines, &c).
It never ends.